
У новай Навукова-даследчая праца апублікавана зялёнай камандай (як выяўлена Карыстальнік Twitter, Redfire).
Даследчая праца NVIDIA распавядае пра «GPU-N» з дызайнам MCM і 8576 ядрамі, ці можа гэта быць Hopper GH100 наступнага пакалення?
У даследчай працы «Спецыялізацыя дамена GPU праз кампазіцыйную архітэктуру на ўпакоўцы» гаворыцца аб канструкцыі графічнага працэсара наступнага пакалення як аб найбольш практычным рашэнні для максімальнай прапускной здольнасці матрыцы з нізкай дакладнасцю для павышэння прадукцыйнасці Deep Learning. «GPU-N» і адпаведныя канструкцыі COPA былі абмеркаваны разам з іх магчымымі спецыфікацыямі і мадэляванымі вынікамі прадукцыйнасці.
Кажуць, што GPU-N мае 134 блокі SM (супраць 104 блокаў SM у A100). Гэта складае ў агульнай складанасці 8576 ядраў або павелічэнне на 24% у параўнанні з бягучым рашэннем Ampere A100. Чып быў вымераны на 1.4 Ггц, такой жа тэарэтычнай тактавай частаце Ampere A100 і Volta V100 (не блытаць з канчатковымі тактамі). Іншыя характарыстыкі ўключаюць 60 МБ кэш-памяці L2, павелічэнне на 50% у параўнанні з Ampere A100 і прапускную здольнасць DRAM 2.68 ТБ/с, якую можна павялічыць да 6.3 ТБ/с. Ёмістасць HBM2e DRAM складае 100 ГБ і можа быць пашырана да 233 ГБ з дапамогай рэалізацыі COPA. Ён сканфігураваны вакол 6144-бітнага інтэрфейсу шыны з тактавай частатой 3.5 Гбіт/с.
| канфігурацыя | NVIDIA V100 | NVIDIA A100 | ГПУ-Н |
|---|---|---|---|
| SMS | 80 | 108 | 134 |
| Частата GPU (Ггц) | 1.4 | 1.4 | 1.4 |
| FP32 (TFLOPS) | 15.7 | 19.5 | 24.2 |
| FP16 (TFLOPS) | 125 | 312 | 779 |
| Кэш L2 (МБ) | 6 | 40 | 60 |
| DRAM BW (ГБ/с) | 900 | 1,555 | 2,687 |
| Ёмістасць DRAM (ГБ) | 16 | 40 | 100 |
Калі казаць пра прадукцыйнасць, то «GPU-N» (меркавана Hopper GH100) стварае 24.2 TFLOPs FP32 (павелічэнне на 24% у параўнанні з A100) і 779 TFLOPs FP16 (павелічэнне ў 2.5x у параўнанні з A100), што гучыць вельмі блізка да 3x прыросту, які быў па чутках, GH100 замест A100. У параўнанні з графічным працэсарам AMD CDNA 2 'Aldebaran' на Паскаральнік Instinct MI250X, прадукцыйнасць FP32 менш чым удвая (95.7 TFLOPs супраць 24.2 TFLOPs), але прадукцыйнасць FP16 у 2.15 разы вышэй.
ад папярэдняя інфармацыя, мы ведаем, што паскаральнік H100 ад NVIDIA будзе заснаваны на рашэнні MCM і будзе выкарыстоўваць 5-нм працэсарны вузел TSMC. Мяркуецца, што Hopper будзе мець два GPU-модулі наступнага пакалення, таму ў агульнай складанасці мы разглядаем 288 адзінак SM. Мы пакуль не можам даць падрабязную інфармацыю аб колькасці ядраў, таму што не ведаем колькасці ядраў у кожнай SM, але калі мы будзем прытрымлівацца 64 ядраў на SM, то атрымаем 18,432 2.25 ядра, што ў 100 раза больш, чым у SM. поўная канфігурацыя GPU GA64. NVIDIA таксама можа выкарыстоўваць больш ядраў FP16, FP1 і Tensor у сваім графічным працэсары Hopper, што значна павысіць прадукцыйнасць. І гэта будзе неабходнасць, каб канкураваць з Ponte Vecchio ад Intel, які, як чакаецца, будзе мець 1:64 FPXNUMX.

Цалкам верагодна, што канчатковая канфігурацыя будзе пастаўляцца са 134 з 144 блокаў SM, уключаных на кожным модулі графічнага працэсара, і, такім чынам, мы, хутчэй за ўсё, глядзім на адзін плашчак GH100 у дзеянні. Але малаверагодна, што NVIDIA дасягнула б такіх жа флопаў FP32 або FP64, што і MI200, без выкарыстання GPU Sparsity.
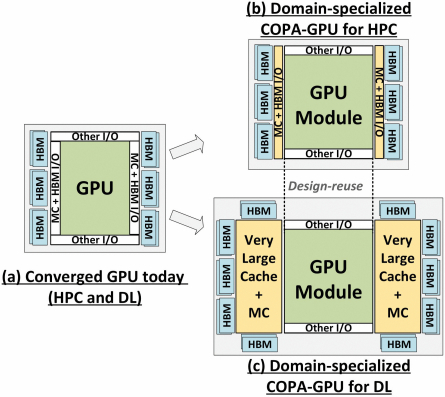
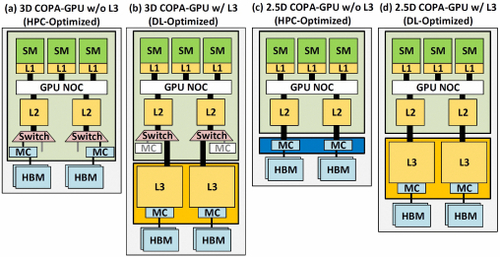
Але NVIDIA можа мець сакрэтную зброю ў сваіх рукавах, і гэта будзе рэалізацыя GPU Hopper на аснове COPA. NVIDIA распавядае аб двух спецыялізаваных на дамене графічных працэсарах COPA, заснаваных на архітэктуры наступнага пакалення: адзін для HPC і другі для сегмента DL. Варыянт HPC мае вельмі стандартны падыход, які складаецца з дызайну графічнага працэсара MCM і адпаведных чыплетаў HBM/MC+HBM (IO), але варыянт DL - гэта тое, дзе ўсё пачынае станавіцца цікавым. Варыянт DL змяшчае велізарны кэш на цалкам асобнай плашцы, якая злучана з модулямі GPU.
| Архітэктура | ТАА Магутнасць | DRAM BW | Ёмістасць DRAM |
|---|---|---|---|
| канфігурацыя | (MB) | (ТБ/с) | (ГБ) |
| ГПУ-Н | 60 | 2.7 | 100 |
| COPA-GPU-1 | 960 | 2.7 | 100 |
| COPA-GPU-2 | 960 | 4.5 | 167 |
| COPA-GPU-3 | 1,920 | 2.7 | 100 |
| COPA-GPU-4 | 1,920 | 4.5 | 167 |
| COPA-GPU-5 | 1,920 | 6.3 | 233 |
| Ідэальны L2 | бясконцы | бясконцы | бясконцы |
Былі акрэслены розныя варыянты з аб'ёмам LLC (кэш апошняга ўзроўню) да 960/1920 ГБ, ёмістасцю DRAM HBM2e да 233 ГБ і прапускной здольнасцю да 6.3 ТБ/с. Усё гэта тэарэтычна, але, улічваючы, што NVIDIA абмеркавала іх зараз, мы можам убачыць варыянт Hopper з такім дызайнам падчас поўнага прадстаўлення на GTC 2022.
NVIDIA Hopper GH100 «Папярэднія характарыстыкі»:
| Відэакарта NVIDIA Tesla | Тэсла К40 (PCI-Express) |
Тэсла М40 (PCI-Express) |
тэсла P100 (PCI-Express) |
Tesla P100 (SXM2) | Тэсла V100 (SXM2) | NVIDIA A100 (SXM4) | NVIDIA H100 (SMX4?) |
|---|---|---|---|---|---|---|---|
| GPU | GK110 (Кеплер) | GM200 (Максвел) | GP100 (Паскаль) | GP100 (Паскаль) | GV100 (Вольта) | GA100 (ампер) | GH100 (бункер) |
| працэс Node | 28nm | 28nm | 16nm | 16nm | 12nm | 7nm | 5nm |
| Транзістары | 7.1 млрд | 8 млрд | 15.3 млрд | 15.3 млрд | 21.1 млрд | 54.2 млрд | TBD |
| Памер GPU Die | 551 mm2 | 601 mm2 | 610 mm2 | 610 mm2 | 815mm2 | 826mm2 | TBD |
| SMS | 15 | 24 | 56 | 56 | 80 | 108 | 134 (на модуль) |
| ТПК | 15 | 24 | 28 | 28 | 40 | 54 | TBD |
| Ядра FP32 CUDA на SM | 192 | 128 | 64 | 64 | 64 | 64 | 64? |
| Ядра FP64 CUDA / SM | 64 | 4 | 32 | 32 | 32 | 32 | 32? |
| FP32 CUDA Core | 2880 | 3072 | 3584 | 3584 | 5120 | 6912 | 8576 (на модуль) 17152 (Поўны) |
| FP64 CUDA Core | 960 | 96 | 1792 | 1792 | 2560 | 3456 | 4288 (на модуль)? 8576 (Поўнае)? |
| Tensor Сардэчнікі | N / A | N / A | N / A | N / A | 640 | 432 | TBD |
| текстурные блокі | 240 | 192 | 224 | 224 | 320 | 432 | TBD |
| павышэнне гадзіны | 875 МГц | 1114 МГц | 1329MHz | 1480 МГц | 1530 МГц | 1410 МГц | ~ 1400 Мгц |
| ТОП (DNN/AI) | N / A | N / A | N / A | N / A | 125 ТОПы | 1248 ТОПы 2496 ТОПаў з Sparsity |
TBD |
| FP16 Compute | N / A | N / A | 18.7 TFLOPS | 21.2 TFLOPS | 30.4 TFLOPS | 312 TFLOPS 624 TFLOPs з Sparsity |
779 TFLOPs (на модуль)? 1558 TFLOPs з разрэджанасцю (на модуль)? |
| FP32 Compute | 5.04 TFLOPS | 6.8 TFLOPS | 10.0 TFLOPS | 10.6 TFLOPS | 15.7 TFLOPS | 19.4 TFLOPS 156 TFLOPs з разрэджанасцю |
24.2 TFLOPs (на модуль)? 193.6 TFLOPs з разрэджанасцю? |
| FP64 Compute | 1.68 TFLOPS | 0.2 TFLOPS | 4.7 TFLOPS | 5.30 TFLOPS | 7.80 TFLOPS | 19.5 TFLOPS (стандарт 9.7 TFLOps) |
24.2 TFLOPs (на модуль)? (стандарт 12.1 TFLOps)? |
| інтэрфейс памяці | 384-бітны GDDR5 | 384-бітны GDDR5 | 4096-бітны HBM2 | 4096-бітны HBM2 | 4096-бітны HBM2 | 6144-бітны HBM2e | 6144-бітны HBM2e |
| Аб'ём памяці | 12 ГБ GDDR5 пры 288 ГБ/с | 24 ГБ GDDR5 пры 288 ГБ/с | 16 ГБ HBM2 пры 732 ГБ/с 12 ГБ HBM2 пры 549 ГБ/с |
16 ГБ HBM2 пры 732 ГБ/с | 16 ГБ HBM2 пры 900 ГБ/с | Да 40 ГБ HBM2 пры 1.6 ТБ/с Да 80 ГБ HBM2 пры 1.6 ТБ/с |
Да 100 ГБ HBM2e пры 3.5 Гбіт/с |
| L2 Памер кэша | 1536 KB | 3072 KB | 4096 KB | 4096 KB | 6144 KB | 40960 KB | 81920 KB |
| TDP | 235W | 250W | 250W | 300W | 300W | 400W | ~ 450-500 Вт |
Паведамленне Таямнічы 'GPU-N' NVIDIA можа быць Hopper GH100 наступнага пакалення, замаскіраваным з 134 SM, 8576 ядраў і прапускной здольнасцю 2.68 ТБ/с, паказаны імітаваныя тэсты прадукцыйнасці by Хасан Муджтаба упершыню з'явіўся на Wccftech.




