
Unha misteriosa GPU NVIDIA coñecida como GPU-N que posiblemente podería ser a primeira ollada ao chip Hopper GH100 de próxima xeración foi revelada nun novo traballo de investigación publicado polo equipo verde (como descubriu Usuario de Twitter, Redfire).
O documento de investigación de NVIDIA fala de 'GPU-N' con deseño MCM e núcleos 8576, podería ser este Hopper GH100 de nova xeración?
O traballo de investigación 'GPU Domain Specialization via Composable On-Package Architecture' fala dun deseño de GPU de próxima xeración como a solución máis práctica para maximizar o rendemento de matemáticas de matriz de baixa precisión para aumentar o rendemento do Deep Learning. A "GPU-N" e os seus respectivos deseños COPA foron discutidos xunto coas súas posibles especificacións e resultados simulados de rendemento.
Dise que a "GPU-N" presenta 134 unidades SM (frente ás 104 unidades SM do A100). Isto supón un total de 8576 núcleos ou un aumento do 24% con respecto á solución Ampere A100 actual. O chip foi medido a 1.4 GHz, a mesma velocidade de reloxo teórica que o Ampere A100 e o Volta V100 (non debe confundirse co reloxo final). Outras especificacións inclúen unha caché L60 de 2 MB, un aumento do 50 % con respecto ao Ampere A100 e un ancho de banda DRAM de 2.68 TB/s que pode escalar ata 6.3 TB/s. A capacidade DRAM HBM2e é de 100 GB e pódese ampliar ata 233 GB coas implementacións COPA. Está configurado arredor dunha interface de bus de 6144 bits a velocidades de reloxo de 3.5 Gbps.
| configuración | NVIDIA V100 | NVIDIA A100 | GPU-N |
|---|---|---|---|
| SMS | 80 | 108 | 134 |
| Frecuencia da GPU (GHz) | 1.4 | 1.4 | 1.4 |
| FP32 (TFLOPS) | 15.7 | 19.5 | 24.2 |
| FP16 (TFLOPS) | 125 | 312 | 779 |
| Caché L2 (MB) | 6 | 40 | 60 |
| DRAM BW (GB/s) | 900 | 1,555 | 2,687 |
| Capacidade DRAM (GB) | 16 | 40 | 100 |
Chegando aos números de rendemento, a "GPU-N" (presumiblemente Hopper GH100) produce 24.2 TFLOP de FP32 (aumento do 24% sobre A100) e 779 TFLOP FP16 (aumento de 2.5 veces sobre A100), o que soa moi preto das ganancias de 3x que foron. rumorea para GH100 sobre A100. En comparación coa GPU "Aldebaran" CDNA 2 de AMD no Acelerador Instinct MI250X, o rendemento do FP32 é inferior á metade (95.7 TFLOP fronte a 24.2 TFLOP) pero o rendemento do FP16 é 2.15 veces superior.
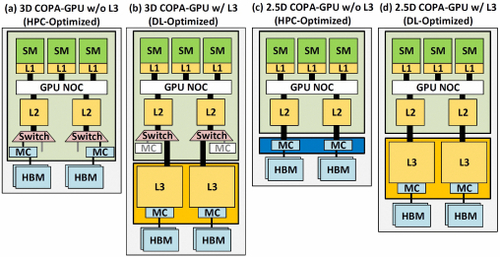
de información previa, sabemos que o acelerador H100 de NVIDIA estaría baseado nunha solución MCM e utilizaría o nodo de proceso de 5 nm de TSMC. Suponse que Hopper ten dous módulos GPU de nova xeración, polo que estamos mirando 288 unidades SM en total. Aínda non podemos dar un resumo do reconto de núcleos xa que non sabemos o número de núcleos que aparecen en cada SM, pero se vai quedar con 64 núcleos por SM, entón teremos 18,432 núcleos, que son 2.25 veces máis que o SM. configuración completa da GPU GA100. NVIDIA tamén podería aproveitar máis núcleos FP64, FP16 e Tensor dentro da súa GPU Hopper, o que aumentaría enormemente o rendemento. E iso vai ser unha necesidade para rivalizar co Ponte Vecchio de Intel, que se espera que conteña FP1 1:64.

É probable que a configuración final veña con 134 das 144 unidades SM habilitadas en cada módulo de GPU e, como tal, é probable que esteamos mirando un único die GH100 en acción. Pero é improbable que NVIDIA alcance os mesmos flops FP32 ou FP64 que os MI200 sen usar GPU Sparsity.
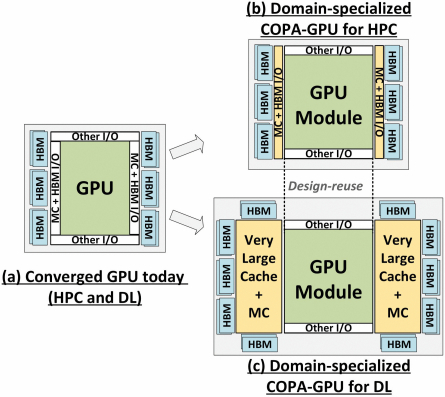
Pero probablemente NVIDIA teña un arma secreta nas súas mangas e esa sería a implementación da GPU baseada en COPA de Hopper. NVIDIA fala de dúas GPU COPA especializadas en dominios baseadas na arquitectura de próxima xeración, unha para HPC e outra para o segmento DL. A variante HPC presenta un enfoque moi estándar que consiste nun deseño de GPU MCM e os respectivos chiplets HBM/MC+HBM (IO), pero a variante DL é onde as cousas comezan a ser interesantes. A variante DL alberga unha enorme caché nun dado totalmente separado que está interconectado cos módulos da GPU.
| arquitectura | Capacidade LLC | DRAM BW | Capacidade DRAM |
|---|---|---|---|
| configuración | (MB) | (TB/s) | (GB) |
| GPU-N | 60 | 2.7 | 100 |
| COPA-GPU-1 | 960 | 2.7 | 100 |
| COPA-GPU-2 | 960 | 4.5 | 167 |
| COPA-GPU-3 | 1,920 | 2.7 | 100 |
| COPA-GPU-4 | 1,920 | 4.5 | 167 |
| COPA-GPU-5 | 1,920 | 6.3 | 233 |
| Perfecto L2 | infinito | infinito | infinito |
Describíronse varias variantes con ata 960/1920 GB de LLC (Last-Level-Cache), capacidades de DRAM HBM2e de ata 233 GB e ancho de banda de ata 6.3 TB/s. Son todos teóricos, pero dado que NVIDIA os comentou agora, é posible que vexamos unha variante de Hopper con tal deseño durante a presentación completa en GTC 2022.
NVIDIA Hopper GH100 "Especificacións preliminares":
| Tarxeta gráfica NVIDIA Tesla | Tesla K40 (PCI Express) |
Tesla M40 (PCI Express) |
Tesla P100 (PCI Express) |
Tesla P100 (SXM2) | Tesla V100 (SXM2) | NVIDIA A100 (SXM4) | NVIDIA H100 (SMX4?) |
|---|---|---|---|---|---|---|---|
| GPU | GK110 (Kepler) | GM200 (Maxwell) | GP100 (Pascal) | GP100 (Pascal) | GV100 (Volta) | GA100 (amperios) | GH100 (Tolva) |
| Nodo de proceso | 28nm | 28nm | 16nm | 16nm | 12nm | 7nm | 5nm |
| Transistores | 7.1 Billion | 8 Billion | 15.3 Billion | 15.3 Billion | 21.1 Billion | 54.2 Billion | TBD |
| Tamaño da matriz da GPU | 551 mm2 | 601 mm2 | 610 mm2 | 610 mm2 | 815mm2 | 826mm2 | TBD |
| SMS | 15 | 24 | 56 | 56 | 80 | 108 | 134 (por módulo) |
| TPC | 15 | 24 | 28 | 28 | 40 | 54 | TBD |
| Núcleos FP32 CUDA por SM | 192 | 128 | 64 | 64 | 64 | 64 | 64? |
| FP64 CUDA Cores/SM | 64 | 4 | 32 | 32 | 32 | 32 | 32? |
| Cores FP32 CUDA | 2880 | 3072 | 3584 | 3584 | 5120 | 6912 | 8576 (por módulo) 17152 (Completo) |
| Cores FP64 CUDA | 960 | 96 | 1792 | 1792 | 2560 | 3456 | 4288 (por módulo)? 8576 (Completo)? |
| Tensor Cores | N / A | N / A | N / A | N / A | 640 | 432 | TBD |
| Unidades de textura | 240 | 192 | 224 | 224 | 320 | 432 | TBD |
| Aumentar o reloxo | 875 MHz | 1114 MHz | 1329MHz | 1480 MHz | 1530 MHz | 1410 MHz | ~ 1400 MHz |
| TOP (DNN/AI) | N / A | N / A | N / A | N / A | TOPS 125 | TOPS 1248 2496 TOPs con sparsity |
TBD |
| Calcula FP16 | N / A | N / A | 18.7 TFLOPs | 21.2 TFLOPs | 30.4 TFLOPs | 312 TFLOPs 624 TFLOP con sparsity |
779 TFLOP (por módulo)? 1558 TFLOP con sparsity (por módulo)? |
| Calcula FP32 | 5.04 TFLOPs | 6.8 TFLOPs | 10.0 TFLOPs | 10.6 TFLOPs | 15.7 TFLOPs | 19.4 TFLOPs 156 TFLOPs con dispersión |
24.2 TFLOP (por módulo)? 193.6 TFLOPs con sparsity? |
| Calcula FP64 | 1.68 TFLOPs | 0.2 TFLOPs | 4.7 TFLOPs | 5.30 TFLOPs | 7.80 TFLOPs | 19.5 TFLOPs (9.7 TFLOP estándar) |
24.2 TFLOP (por módulo)? (12.1 TFLOP estándar)? |
| Interface de memoria | GDDR384 de 5 bits | GDDR384 de 5 bits | HBM4096 de 2 bits | HBM4096 de 2 bits | HBM4096 de 2 bits | HBM6144e de 2 bits | HBM6144e de 2 bits |
| Tamaño da memoria | 12 GB GDDR5 @ 288 GB/s | 24 GB GDDR5 @ 288 GB/s | 16 GB HBM2 @ 732 GB/s 12 GB HBM2 @ 549 GB/s |
16 GB HBM2 @ 732 GB/s | 16 GB HBM2 @ 900 GB/s | Ata 40 GB HBM2 @ 1.6 TB/s Ata 80 GB HBM2 @ 1.6 TB/s |
Ata 100 GB HBM2e @ 3.5 Gbps |
| Tamaño da caché L2 | 1536 KB | 3072 KB | 4096 KB | 4096 KB | 6144 KB | 40960 KB | 81920 KB |
| TDP | 235W | 250W | 250W | 300W | 300W | 400W | ~ 450-500W |
O posto O misterioso 'GPU-N' de NVIDIA podería ser un Hopper GH100 de nova xeración disfrazado con 134 SM, 8576 núcleos e ancho de banda de 2.68 TB/s, mostrando puntos de referencia de rendemento simulados by Hassan Mukhtaba apareceu por primeira vez en Wccftech.




